Synopsis
JRuby is an implementation of Ruby on the JVM. It aims to be a complete, correct and fast implementation of Ruby, at the same time as providing powerful new features such as concurrency without a global-interpreter-lock, true parallelism, and tight integration to the Java language to allow you to use Java classes in your Ruby program and to allow JRuby to be embedded into a Java application.
As one of the JRuby features is fast, I want to look into improving the performance of JRuby's hash implementation. JRuby still uses a closed address hash algorithm with a linked list. As it turned out, this approach has some performance implications in terms of cache locality on modern CPU architectures. Some programming languages recently switched to an open address hash algorithm (including MRI since 2.4 itself) which turns out to better make use of cache locality.
Furthermore I want to improve memory allocation for small hashes by using a simple linear search instead of any hash algorithm as for small hashes this will likely have no performance issue at all.
Result
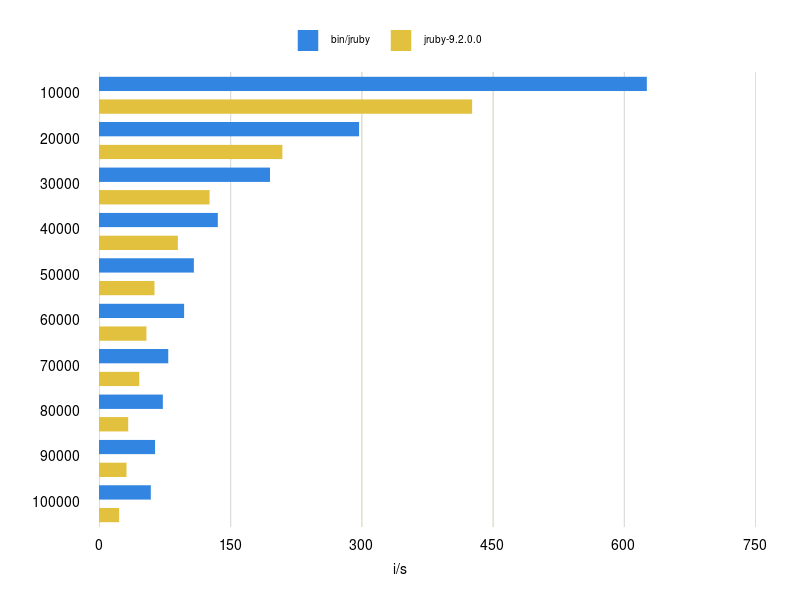
Code is already merged upstream and will be released with JRuby 9.2.1.0. Large hash tables are up to two times faster than before.
For detailed results see this blog post. The PR can be found here.

Looking for hackers with the skills:
Nothing? Add some keywords!
This project is part of:
Hack Week 17
Activity
Comments
Be the first to comment!
Similar Projects
This project is one of its kind!