Project Description
BPF verifier plays a crucial role in securing the system (though less so now that unprivileged BPF is disabled by default in both upstream and SLES), and bugs in the verifier has lead to privilege escalation vulnerabilities in the past (e.g. CVE-2021-3490).
One way to check whether the verifer has bugs to use model checking (a formal verification technique), in other words, build a abstract model of how the verifier operates, and then see if certain condition can occur (e.g. incorrect calculation during value tracking of registers) by giving both the model and condition to a solver.
For the solver I will be using the Z3 SMT solver to do the checking since it provide a Python binding that's relatively easy to use.
Goal for this Hackweek
Learn how to use the Z3 Python binding (i.e. Z3Py) to build a model of (part of) the BPF verifier, probably the part that's related to value tracking using tristate numbers (aka tnum), and then check that the algorithm work as intended.
Resources
- Formal Methods for the Informal Engineer: Tutorial #1 - The Z3 Theorem Prover and its accompanying notebook is a great introduction into Z3
- Has a section specifically on model checking
- Software Verification and Analysis Using Z3 a great example of using Z3 for model checking
- Sound, Precise, and Fast Abstract Interpretation with Tristate Numbers - existing work that use formal verification to prove that the multiplication helper used for value tracking work as intended
- [PATCH v5 net-next 00/12] bpf: rewrite value tracking in verifier - initial patch set that adds tristate number to the verifier

Looking for hackers with the skills:
This project is part of:
Hack Week 21 Hack Week 23 Hack Week 24
Activity
Comments
-

over 3 years ago by shunghsiyu | Reply
I've uploaded the jupyter notebook on GitHub that contains a minimal model of tnum along with tnum_add(), as well as the prove that it works.
-
over 3 years ago by shunghsiyu | Reply
The slides used for lightning talk can be found here
While I'd like to achieve much more, I think what I've done during hack week is suffice to be called a complete project, so I'm marking this as complete
-
over 2 years ago by shunghsiyu | Reply
I'm restarting this project to model check the range tracking (minimal and maximal value possible in s32/u32/u64/s64 range) done in BPF verifier.
In addition to that I hope to unify signed and unsigned range tracking based on previously posted idea and the "Interval Analysis and Machine Arithmetic: Why Signedness Ignorance Is Bliss" paper for simpler range tracking code.
Similar Projects
bpftrace contribution by mkoutny
Description
bpftrace is a great tool, no need to sing odes to it here. It can access any kernel data and process them in real time. It provides helpers for some common Linux kernel structures but not all.
Goals
- set up bpftrace toolchain
- learn about bpftrace implementation and internals
- implement support for
percpu_counters - look into some of the first issues
- send a refined PR (on Thu)
Resources
eBPF bytecode emitter in Haskell by kalfalakh
Description
Newbie level knowledge of eBPF and some knowledge of Haskell. The goal for this hackweek is to catch two birds with one stone; get familiar with eBPF and learn more about Haskell, hence implement something related to eBPF in Haskell. Given an input, which is a program, represented as eBPF instructions, prepare a fully built eBPF bytecode ready to be loaded into the Kernel.
Goals
- Recap on ADTs in Haskell, type classes and their instances / deriving, on pattern matching and higher order functions
- Read and understand RFC 9669
- Implement the entire pipeline; parsing the input, verifying the input, building instructions, encoding them and concatenating them
- Deal with all the learning, bugs and difficulties encountered on the way
Progress
Last day of hackweek and this is what I have so far.
- ADTs implemented to correctly type all operations, classes, opcodes, instructions and other instruction specific types
- opcodes and opcode builders based on specification are implemented.
- Encoder is ready for 64-bit instruction format. Extended 128-bit instruction format is not yet supported
- Only ALU and ALU64 instructions API is provided. JMP, LD, ST for base32 and base64 are missing. swap and atomic are missing
- All ALU and ALU64 instructions (except MOV and MOVSX) are tested manually and are correctly encoded
Whats next?
There is still a lot left to do:
- Input parser and formatter + some kind of basic verifier
- API for remaining instruction classes
- Proper testing mechanism
- swap and atomic instructions
- Loader
Resources
- RFC 9669
- https://ebpf.io/
- https://www.haskell.org/documentation/
Improve UML page fault handler by ptesarik
Description
Improve UML handling of segmentation faults in kernel mode. Although such page faults are generally caused by a kernel bug, it is annoying if they cause an infinite loop, or panic the kernel. More importantly, a robust implementation allows to write KUnit tests for various guard pages, preventing potential kernel self-protection regressions.
Goals
Convert the UML page fault handler to use oops_* helpers, go through a few review rounds and finally get my patch series merged in 6.14.
Resources
Wrong initial attempt: https://lore.kernel.org/lkml/20231215121431.680-1-petrtesarik@huaweicloud.com/T/
dynticks-testing: analyse perf / trace-cmd output and aggregate data by m.crivellari
Description
dynticks-testing is a project started years ago by Frederic Weisbecker. One of the feature is to check the actual configuration (isolcpus, irqaffinity etc etc) and give feedback on it.
An important goal of this tool is to parse the output of trace-cmd / perf and provide more readable data, showing the duration of every events grouped by PID (showing also the CPU number, if the tasks has been migrated etc).
An example of data captured on my laptop (incomplete!!):
-0 [005] dN.2. 20310.270699: sched_wakeup: WaylandProxy:46380 [120] CPU:005
-0 [005] d..2. 20310.270702: sched_switch: swapper/5:0 [120] R ==> WaylandProxy:46380 [120]
...
WaylandProxy-46380 [004] d..2. 20310.295397: sched_switch: WaylandProxy:46380 [120] S ==> swapper/4:0 [120]
-0 [006] d..2. 20310.295397: sched_switch: swapper/6:0 [120] R ==> firefox:46373 [120]
firefox-46373 [006] d..2. 20310.295408: sched_switch: firefox:46373 [120] S ==> swapper/6:0 [120]
-0 [004] dN.2. 20310.295466: sched_wakeup: WaylandProxy:46380 [120] CPU:004
Output of noise_parse.py:
Task: WaylandProxy Pid: 46380 cpus: {4, 5} (Migrated!!!)
Wakeup Latency Nr: 24 Duration: 89
Sched switch: kworker/12:2 Nr: 1 Duration: 6
My first contribution is around Nov. 2024!
Goals
- add more features (eg cpuset)
- test / bugfix
Resources
- Frederic's public repository: https://git.kernel.org/pub/scm/linux/kernel/git/frederic/dynticks-testing.git/
- https://docs.kernel.org/timers/no_hz.html#testing
Progresses
isolcpus and cpusets implemented and merged in master: dynticks-testing.git commit
pudc - A PID 1 process that barks to the internet by mssola
Description
As a fun exercise in order to dig deeper into the Linux kernel, its interfaces, the RISC-V architecture, and all the dragons in between; I'm building a blog site cooked like this:
- The backend is written in a mixture of C and RISC-V assembly.
- The backend is actually PID1 (for real, not within a container).
- We poll and parse incoming HTTP requests ourselves.
- The frontend is a mere HTML page with htmx.
The project is meant to be Linux-specific, so I'm going to use io_uring, pidfs, namespaces, and Linux-specific features in order to drive all of this.
I'm open for suggestions and so on, but this is meant to be a solo project, as this is more of a learning exercise for me than anything else.
Goals
- Have a better understanding of different Linux features from user space down to the kernel internals.
- Most importantly: have fun.
Resources
bpftrace contribution by mkoutny
Description
bpftrace is a great tool, no need to sing odes to it here. It can access any kernel data and process them in real time. It provides helpers for some common Linux kernel structures but not all.
Goals
- set up bpftrace toolchain
- learn about bpftrace implementation and internals
- implement support for
percpu_counters - look into some of the first issues
- send a refined PR (on Thu)
Resources
early stage kdump support by mbrugger
Project Description
When we experience a early boot crash, we are not able to analyze the kernel dump, as user-space wasn't able to load the crash system. The idea is to make the crash system compiled into the host kernel (think of initramfs) so that we can create a kernel dump really early in the boot process.
Goal for the Hackweeks
- Investigate if this is possible and the implications it would have (done in HW21)
- Hack up a PoC (done in HW22 and HW23)
- Prepare RFC series (giving it's only one week, we are entering wishful thinking territory here).
update HW23
- I was able to include the crash kernel into the kernel Image.
- I'll need to find a way to load that from
init/main.c:start_kernel()probably afterkcsan_init() - I workaround for a smoke test was to hack
kexec_file_load()systemcall which has two problems:- My initramfs in the porduction kernel does not have a new enough kexec version, that's not a blocker but where the week ended
- As the crash kernel is part of init.data it will be already stale once I can call
kexec_file_load()from user-space.
The solution is probably to rewrite the POC so that the invocation can be done from init.text (that's my theory) but I'm not sure if I can reuse the kexec infrastructure in the kernel from there, which I rely on heavily.
update HW24
- Day1
- rebased on v6.12 with no problems others then me breaking the config
- setting up a new compilation and qemu/virtme env
- getting desperate as nothing works that used to work
- Day 2
- getting to call the invocation of loading the early kernel from
__initafterkcsan_init()
- getting to call the invocation of loading the early kernel from
Day 3
- fix problem of memdup not being able to alloc so much memory... use 64K page sizes for now
- code refactoring
- I'm now able to load the crash kernel
- When using virtme I can boot into the crash kernel, also it doesn't boot completely (major milestone!), crash in
elfcorehdr_read_notes()
Day 4
- crash systems crashes (no pun intended) in
copy_old_mempage()link; will need to understand elfcorehdr... - call path
vmcore_init() -> parse_crash_elf_headers() -> elfcorehdr_read() -> read_from_oldmem() -> copy_oldmem_page() -> copy_to_iter()
- crash systems crashes (no pun intended) in
Day 5
- hacking
arch/arm64/kernel/crash_dump.c:copy_old_mempage()to see if crash system really starts. It does. - fun fact: retested with more reserved memory and with UEFI FW, host kernel crashes in init but directly starts the crash kernel, so it works (somehow) \o/
- hacking
update HW25
- Day 1
- rebased crash-kernel on v6.12.59 (for now), still crashing
Exploring Rust's potential: from basics to security by sferracci
Description
This project aims to conduct a focused investigation and practical application of the Rust programming language, with a specific emphasis on its security model. A key component will be identifying and understanding the most common vulnerabilities that can be found in Rust code.
Goals
Achieve a beginner/intermediate level of proficiency in writing Rust code. This will be measured by trying to solve LeetCode problems focusing on common data structures and algorithms. Study Rust vulnerabilities and learning best practices to avoid them.
Resources
Rust book: https://doc.rust-lang.org/book/
Looking at Rust if it could be an interesting programming language by jsmeix
Get some basic understanding of Rust security related features from a general point of view.
This Hack Week project is not to learn Rust to become a Rust programmer. This might happen later but it is not the goal of this Hack Week project.
The goal of this Hack Week project is to evaluate if Rust could be an interesting programming language.
An interesting programming language must make it easier to write code that is correct and stays correct when over time others maintain and enhance it than the opposite.
vex8s-controller: a kubernetes controller to automatically generate VEX documents of your running workloads by agreggi

Description
vex8s-controller is an add-on for SBOMscanner project.
Its purpose is to automatically generate VEX documents based on the workloads running in a kubernetes cluster. It integrates directly with SBOMscanner by monitoring VulnerabilityReports created for container images and producing corresponding VEX documents that reflect each workload’s SecurityContext.
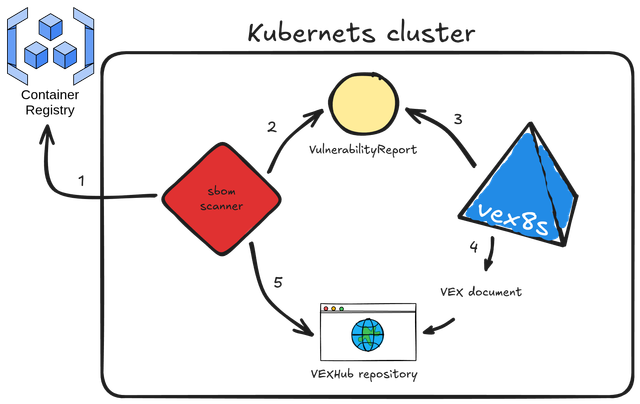
Here's the workflow explained:
- sbomscanner scans for images in registry
- generates a
VulnerabilityReportwith the image CVEs - vex8s-controller triggers when a workload is scheduled on the cluster and generates a VEX document based on the workload
SecurityContextconfiguration - the VEX document is provided by vex8s-controller using a VEX Hub repository
- sbomscanner configure the VEXHub CRD to point to the internal vex8s-controller VEX Hub repository
Goals
The objective is to build a kubernetes controller that uses the vex8s mitigation rules engine to generate VEX documents and serve them through an internal VEX Hub repository within the cluster.
SBOMscanner can then be configured to consume VEX data directly from this in-cluster repository managed by vex8s-controller.
Resources
Summary
The project ended up with this PoC on GitHub: vex8s-controller.
The controller works fine, but needs work to make it more stable. Instructions to reproduce a demo locally are reported in the repository.
Help Create A Chat Control Resistant Turnkey Chatmail/Deltachat Relay Stack - Rootless Podman Compose, OpenSUSE BCI, Hardened, & SELinux by 3nd5h1771fy
Description
The Mission: Decentralized & Sovereign Messaging
FYI: If you have never heard of "Chatmail", you can visit their site here, but simply put it can be thought of as the underlying protocol/platform decentralized messengers like DeltaChat use for their communications. Do not confuse it with the honeypot looking non-opensource paid for prodect with better seo that directs you to chatmailsecure(dot)com
In an era of increasing centralized surveillance by unaccountable bad actors (aka BigTech), "Chat Control," and the erosion of digital privacy, the need for sovereign communication infrastructure is critical. Chatmail is a pioneering initiative that bridges the gap between classic email and modern instant messaging, offering metadata-minimized, end-to-end encrypted (E2EE) communication that is interoperable and open.
However, unless you are a seasoned sysadmin, the current recommended deployment method of a Chatmail relay is rigid, fragile, difficult to properly secure, and effectively takes over the entire host the "relay" is deployed on.
Why This Matters
A simple, host agnostic, reproducible deployment lowers the entry cost for anyone wanting to run a privacy‑preserving, decentralized messaging relay. In an era of perpetually resurrected chat‑control legislation threats, EU digital‑sovereignty drives, and many dangers of using big‑tech messaging platforms (Apple iMessage, WhatsApp, FB Messenger, Instagram, SMS, Google Messages, etc...) for any type of communication, providing an easy‑to‑use alternative empowers:
- Censorship resistance - No single entity controls the relay; operators can spin up new nodes quickly.
- Surveillance mitigation - End‑to‑end OpenPGP encryption ensures relay operators never see plaintext.
- Digital sovereignty - Communities can host their own infrastructure under local jurisdiction, aligning with national data‑policy goals.
By turning the Chatmail relay into a plug‑and‑play container stack, we enable broader adoption, foster a resilient messaging fabric, and give developers, activists, and hobbyists a concrete tool to defend privacy online.
Goals
As I indicated earlier, this project aims to drastically simplify the deployment of Chatmail relay. By converting this architecture into a portable, containerized stack using Podman and OpenSUSE base container images, we can allow anyone to deploy their own censorship-resistant, privacy-preserving communications node in minutes.
Our goal for Hack Week: package every component into containers built on openSUSE/MicroOS base images, initially orchestrated with a single container-compose.yml (podman-compose compatible). The stack will:
- Run on any host that supports Podman (including optimizations and enhancements for SELinux‑enabled systems).
- Allow network decoupling by refactoring configurations to move from file-system constrained Unix sockets to internal TCP networking, allowing containers achieve stricter isolation.
- Utilize Enhanced Security with SELinux by using purpose built utilities such as udica we can quickly generate custom SELinux policies for the container stack, ensuring strict confinement superior to standard/typical Docker deployments.
- Allow the use of bind or remote mounted volumes for shared data (
/var/vmail, DKIM keys, TLS certs, etc.). - Replace the local DNS server requirement with a remote DNS‑provider API for DKIM/TXT record publishing.
By delivering a turnkey, host agnostic, reproducible deployment, we lower the barrier for individuals and small communities to launch their own chatmail relays, fostering a decentralized, censorship‑resistant messaging ecosystem that can serve DeltaChat users and/or future services adopting this protocol
Resources
- The links included above
- https://chatmail.at/doc/relay/
- https://delta.chat/en/help
- Project repo -> https://codeberg.org/EndShittification/containerized-chatmail-relay
OSHW USB token for Passkeys (FIDO2, U2F, WebAuthn) and PGP by duwe
Description
The idea to carry your precious key material along in a specially secured hardware item is almost as old as public keys themselves, starting with the OpenPGP card. Nowadays, an USB plug or NFC are the hardware interfaces of choice, and password-less log-ins are fortunately becoming more popular and standardised.
Meanwhile there are a few products available in that field, for example
yubikey - the "market leader", who continues to sell off buggy, allegedly unfixable firmware ROMs from old stock. Needless to say, it's all but open source, so assume backdoors.
nitrokey - the "start" variant is open source, but the hardware was found to leak its flash ROM content via the SWD debugging interface (even when the flash is read protected !) Compute power is barely enough for Curve25519, Flash memory leaves room for only 3 keys.
solokey(2) - quite neat hardware, with a secure enclave called "TrustZone-M". Unfortunately, the OSS firmware development is stuck in a rusty dead end and cannot use it. Besides, NXP's support for open source toolchains for its devboards is extremely limited.
I plan to base this project on the not-so-tiny USB stack, which is extremely easy to retarget, and to rewrite / refactor the crypto protocols to use the keys only via handles, so the actual key material can be stored securely. Best OSS support seems to be for STM32-based products.
Goals
Create a proof-of-concept item that can provide a second factor for logins and/or decrypt a PGP mail with your private key without disclosing the key itself. Implement or at least show a migration path to store the private key in a location with elevated hardware security.
Resources
STM32 Nucleo, blackmagic probe, tropicsquare tropic01, arm-none cross toolchain