In the past I've worked on a set of scripts to identify potential for improvement of the supply chain within our build service. For now RPM files can be scanned for unused signature files that are available upstream and look for potentially unused https:// links, although they are available.
These scripts work on a prototype-basis, but there is a lot of follow-up work to do, e.g.:
- Re-structuring and tidying up the source
- Improve the API of the libraries
- Implement advanced features (look through all of the existing
# TODOcomments) - Add test cases to make scripts and libraries more robust
- Move from GitHub to internal GitLab instance
- Implement robust continuous integration
- Create script that will scan through the (Factory) source tree on a regular basis
No Hackers yet
Looking for hackers with the skills:
This project is part of:
Hack Week 17
Activity
Comments
Be the first to comment!
Similar Projects
Advent of Code: The Diaries by amanzini
Description
It was the Night Before Compile Time ...
Hackweek 25 (December 1-5) perfectly coincides with the first five days of Advent of Code 2025. This project will leverage this overlap to participate in the event in real-time.
To add a layer of challenge and exploration (in the true spirit of Hackweek), the puzzles will be solved using a non-mainstream, modern language like Ruby, D, Crystal, Gleam or Zig.
The primary project intent is not just simply to solve the puzzles, but to exercise result sharing and documentation. I'd create a public-facing repository documenting the process. This involves treating each day's puzzle as a mini-project: solving it, then documenting the solution with detailed write-ups, analysis of the language's performance and ergonomics, and visualizations.
|
\ ' /
-- (*) --
>*<
>0<@<
>>>@<<*
>@>*<0<<<
>*>>@<<<@<<
>@>>0<<<*<<@<
>*>>0<<@<<<@<<<
>@>>*<<@<>*<<0<*<
\*/ >0>>*<<@<>0><<*<@<<
___\\U//___ >*>>@><0<<*>>@><*<0<<
|\\ | | \\| >@>>0<*<0>>@<<0<<<*<@<<
| \\| | _(UU)_ >((*))_>0><*<0><@<<<0<*<
|\ \| || / //||.*.*.*.|>>@<<*<<@>><0<<<
|\\_|_|&&_// ||*.*.*.*|_\\db//_
""""|'.'.'.|~~|.*.*.*| ____|_
|'.'.'.| ^^^^^^|____|>>>>>>|
~~~~~~~~ '""""`------'
------------------------------------------------
This ASCII pic can be found at
https://asciiart.website/art/1831
Goals
Code, Docs, and Memes: An AoC Story
Have fun!
Involve more people, play together
Solve Days 1-5: Successfully solve both parts of the Advent of Code 2025 puzzles for Days 1-5 using the chosen non-mainstream language.
Daily Documentation & Language Review: Publish a detailed write-up for each day. This documentation will include the solution analysis, the chosen algorithm, and specific commentary on the language's ergonomics, performance, and standard library for the given task.
Bring to Cockpit + System Roles capabilities from YAST by miguelpc
Bring to Cockpit + System Roles features from YAST
Cockpit and System Roles have been added to SLES 16 There are several capabilities in YAST that are not yet present in Cockpit and System Roles We will follow the principle of "automate first, UI later" being System Roles the automation component and Cockpit the UI one.
Goals
The idea is to implement service configuration in System Roles and then add an UI to manage these in Cockpit. For some capabilities it will be required to have an specific Cockpit Module as they will interact with a reasource already configured.
Resources
A plan on capabilities missing and suggested implementation is available here: https://docs.google.com/spreadsheets/d/1ZhX-Ip9MKJNeKSYV3bSZG4Qc5giuY7XSV0U61Ecu9lo/edit
Linux System Roles:
- https://linux-system-roles.github.io/
- https://build.opensuse.org/package/show/openSUSE:Factory/ansible-linux-system-roles Package on sle16 ansible-linux-system-roles
First meeting Hackweek catchup
- Monday, December 1 · 11:00 – 12:00
- Time zone: Europe/Madrid
- Google Meet link: https://meet.google.com/rrc-kqch-hca
Improve/rework household chore tracker `chorazon` by gniebler
Description
I wrote a household chore tracker named chorazon, which is meant to be deployed as a web application in the household's local network.
It features the ability to set up different (so far only weekly) schedules per task and per person, where tasks may span several days.
There are "tokens", which can be collected by users. Tasks can (and usually will) have rewards configured where they yield a certain amount of tokens. The idea is that they can later be redeemed for (surprise) gifts, but this is not implemented yet. (So right now one needs to edit the DB manually to subtract tokens when they're redeemed.)
Days are not rolled over automatically, to allow for task completion control.
We used it in my household for several months, with mixed success. There are many limitations in the system that would warrant a revisit.
It's written using the Pyramid Python framework with URL traversal, ZODB as the data store and Web Components for the frontend.
Goals
- Add admin screens for users, tasks and schedules
- Add models, pages etc. to allow redeeming tokens for gifts/surprises
- …?
Resources
tbd (Gitlab repo)
Help Create A Chat Control Resistant Turnkey Chatmail/Deltachat Relay Stack - Rootless Podman Compose, OpenSUSE BCI, Hardened, & SELinux by 3nd5h1771fy
Description
The Mission: Decentralized & Sovereign Messaging
FYI: If you have never heard of "Chatmail", you can visit their site here, but simply put it can be thought of as the underlying protocol/platform decentralized messengers like DeltaChat use for their communications. Do not confuse it with the honeypot looking non-opensource paid for prodect with better seo that directs you to chatmailsecure(dot)com
In an era of increasing centralized surveillance by unaccountable bad actors (aka BigTech), "Chat Control," and the erosion of digital privacy, the need for sovereign communication infrastructure is critical. Chatmail is a pioneering initiative that bridges the gap between classic email and modern instant messaging, offering metadata-minimized, end-to-end encrypted (E2EE) communication that is interoperable and open.
However, unless you are a seasoned sysadmin, the current recommended deployment method of a Chatmail relay is rigid, fragile, difficult to properly secure, and effectively takes over the entire host the "relay" is deployed on.
Why This Matters
A simple, host agnostic, reproducible deployment lowers the entry cost for anyone wanting to run a privacy‑preserving, decentralized messaging relay. In an era of perpetually resurrected chat‑control legislation threats, EU digital‑sovereignty drives, and many dangers of using big‑tech messaging platforms (Apple iMessage, WhatsApp, FB Messenger, Instagram, SMS, Google Messages, etc...) for any type of communication, providing an easy‑to‑use alternative empowers:
- Censorship resistance - No single entity controls the relay; operators can spin up new nodes quickly.
- Surveillance mitigation - End‑to‑end OpenPGP encryption ensures relay operators never see plaintext.
- Digital sovereignty - Communities can host their own infrastructure under local jurisdiction, aligning with national data‑policy goals.
By turning the Chatmail relay into a plug‑and‑play container stack, we enable broader adoption, foster a resilient messaging fabric, and give developers, activists, and hobbyists a concrete tool to defend privacy online.
Goals
As I indicated earlier, this project aims to drastically simplify the deployment of Chatmail relay. By converting this architecture into a portable, containerized stack using Podman and OpenSUSE base container images, we can allow anyone to deploy their own censorship-resistant, privacy-preserving communications node in minutes.
Our goal for Hack Week: package every component into containers built on openSUSE/MicroOS base images, initially orchestrated with a single container-compose.yml (podman-compose compatible). The stack will:
- Run on any host that supports Podman (including optimizations and enhancements for SELinux‑enabled systems).
- Allow network decoupling by refactoring configurations to move from file-system constrained Unix sockets to internal TCP networking, allowing containers achieve stricter isolation.
- Utilize Enhanced Security with SELinux by using purpose built utilities such as udica we can quickly generate custom SELinux policies for the container stack, ensuring strict confinement superior to standard/typical Docker deployments.
- Allow the use of bind or remote mounted volumes for shared data (
/var/vmail, DKIM keys, TLS certs, etc.). - Replace the local DNS server requirement with a remote DNS‑provider API for DKIM/TXT record publishing.
By delivering a turnkey, host agnostic, reproducible deployment, we lower the barrier for individuals and small communities to launch their own chatmail relays, fostering a decentralized, censorship‑resistant messaging ecosystem that can serve DeltaChat users and/or future services adopting this protocol
Resources
- The links included above
- https://chatmail.at/doc/relay/
- https://delta.chat/en/help
- Project repo -> https://codeberg.org/EndShittification/containerized-chatmail-relay
Improve chore and screen time doc generator script `wochenplaner` by gniebler
Description
I wrote a little Python script to generate PDF docs, which can be used to track daily chore completion and screen time usage for several people, with one page per person/week.
I named this script wochenplaner and have been using it for a few months now.
It needs some improvements and adjustments in how the screen time should be tracked and how chores are displayed.
Goals
- Fix chore field separation lines
- Change screen time tracking logic from "global" (week-long) to daily subtraction and weekly addition of remainders (more intuitive than current "weekly time budget method)
- Add logic to fill in chore fields/lines, ideally with pictures, falling back to text.
Resources
tbd (Gitlab repo)
Collection and organisation of information about Bulgarian schools by iivanov
Description
To achieve this it will be necessary:
- Collect/download raw data from various government and non-governmental organizations
- Clean up raw data and organise it in some kind database.
- Create tool to make queries easy.
- Or perhaps dump all data into AI and ask questions in natural language.
Goals
By selecting particular school information like this will be provided:
- School scores on national exams.
- School scores from the external evaluations exams.
- School town, municipality and region.
- Employment rate in a town or municipality.
- Average health of the population in the region.
Resources
Some of these are available only in bulgarian.
- https://danybon.com/klasazia
- https://nvoresults.com/index.html
- https://ri.mon.bg/active-institutions
- https://www.nsi.bg/nrnm/ekatte/archive
Results
- Information about all Bulgarian schools with their scores during recent years cleaned and organised into SQL tables
- Information about all Bulgarian villages, cities, municipalities and districts cleaned and organised into SQL tables
- Information about all Bulgarian villages and cities census since beginning of this century cleaned and organised into SQL tables.
- Information about all Bulgarian municipalities about religion, ethnicity cleaned and organised into SQL tables.
- Data successfully loaded to locally running Ollama with help to Vanna.AI
- Seems to be usable.
TODO
- Add more statistical information about municipalities and ....
Code and data
OSHW USB token for Passkeys (FIDO2, U2F, WebAuthn) and PGP by duwe
Description
The idea to carry your precious key material along in a specially secured hardware item is almost as old as public keys themselves, starting with the OpenPGP card. Nowadays, an USB plug or NFC are the hardware interfaces of choice, and password-less log-ins are fortunately becoming more popular and standardised.
Meanwhile there are a few products available in that field, for example
yubikey - the "market leader", who continues to sell off buggy, allegedly unfixable firmware ROMs from old stock. Needless to say, it's all but open source, so assume backdoors.
nitrokey - the "start" variant is open source, but the hardware was found to leak its flash ROM content via the SWD debugging interface (even when the flash is read protected !) Compute power is barely enough for Curve25519, Flash memory leaves room for only 3 keys.
solokey(2) - quite neat hardware, with a secure enclave called "TrustZone-M". Unfortunately, the OSS firmware development is stuck in a rusty dead end and cannot use it. Besides, NXP's support for open source toolchains for its devboards is extremely limited.
I plan to base this project on the not-so-tiny USB stack, which is extremely easy to retarget, and to rewrite / refactor the crypto protocols to use the keys only via handles, so the actual key material can be stored securely. Best OSS support seems to be for STM32-based products.
Goals
Create a proof-of-concept item that can provide a second factor for logins and/or decrypt a PGP mail with your private key without disclosing the key itself. Implement or at least show a migration path to store the private key in a location with elevated hardware security.
Resources
STM32 Nucleo, blackmagic probe, tropicsquare tropic01, arm-none cross toolchain
vex8s-controller: a kubernetes controller to automatically generate VEX documents of your running workloads by agreggi

Description
vex8s-controller is an add-on for SBOMscanner project.
Its purpose is to automatically generate VEX documents based on the workloads running in a kubernetes cluster. It integrates directly with SBOMscanner by monitoring VulnerabilityReports created for container images and producing corresponding VEX documents that reflect each workload’s SecurityContext.
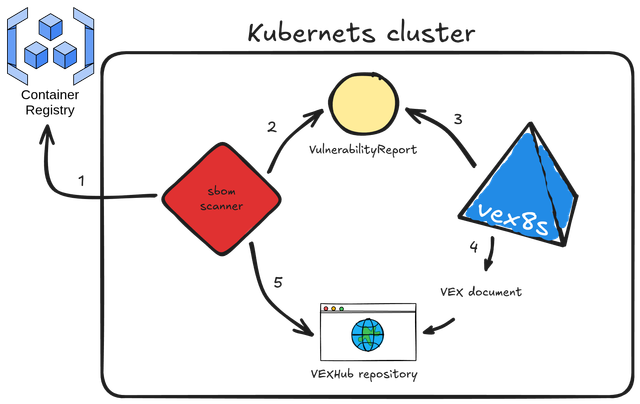
Here's the workflow explained:
- sbomscanner scans for images in registry
- generates a
VulnerabilityReportwith the image CVEs - vex8s-controller triggers when a workload is scheduled on the cluster and generates a VEX document based on the workload
SecurityContextconfiguration - the VEX document is provided by vex8s-controller using a VEX Hub repository
- sbomscanner configure the VEXHub CRD to point to the internal vex8s-controller VEX Hub repository
Goals
The objective is to build a kubernetes controller that uses the vex8s mitigation rules engine to generate VEX documents and serve them through an internal VEX Hub repository within the cluster.
SBOMscanner can then be configured to consume VEX data directly from this in-cluster repository managed by vex8s-controller.
Resources
Summary
The project ended up with this PoC on GitHub: vex8s-controller.
The controller works fine, but needs work to make it more stable. Instructions to reproduce a demo locally are reported in the repository.
Help Create A Chat Control Resistant Turnkey Chatmail/Deltachat Relay Stack - Rootless Podman Compose, OpenSUSE BCI, Hardened, & SELinux by 3nd5h1771fy
Description
The Mission: Decentralized & Sovereign Messaging
FYI: If you have never heard of "Chatmail", you can visit their site here, but simply put it can be thought of as the underlying protocol/platform decentralized messengers like DeltaChat use for their communications. Do not confuse it with the honeypot looking non-opensource paid for prodect with better seo that directs you to chatmailsecure(dot)com
In an era of increasing centralized surveillance by unaccountable bad actors (aka BigTech), "Chat Control," and the erosion of digital privacy, the need for sovereign communication infrastructure is critical. Chatmail is a pioneering initiative that bridges the gap between classic email and modern instant messaging, offering metadata-minimized, end-to-end encrypted (E2EE) communication that is interoperable and open.
However, unless you are a seasoned sysadmin, the current recommended deployment method of a Chatmail relay is rigid, fragile, difficult to properly secure, and effectively takes over the entire host the "relay" is deployed on.
Why This Matters
A simple, host agnostic, reproducible deployment lowers the entry cost for anyone wanting to run a privacy‑preserving, decentralized messaging relay. In an era of perpetually resurrected chat‑control legislation threats, EU digital‑sovereignty drives, and many dangers of using big‑tech messaging platforms (Apple iMessage, WhatsApp, FB Messenger, Instagram, SMS, Google Messages, etc...) for any type of communication, providing an easy‑to‑use alternative empowers:
- Censorship resistance - No single entity controls the relay; operators can spin up new nodes quickly.
- Surveillance mitigation - End‑to‑end OpenPGP encryption ensures relay operators never see plaintext.
- Digital sovereignty - Communities can host their own infrastructure under local jurisdiction, aligning with national data‑policy goals.
By turning the Chatmail relay into a plug‑and‑play container stack, we enable broader adoption, foster a resilient messaging fabric, and give developers, activists, and hobbyists a concrete tool to defend privacy online.
Goals
As I indicated earlier, this project aims to drastically simplify the deployment of Chatmail relay. By converting this architecture into a portable, containerized stack using Podman and OpenSUSE base container images, we can allow anyone to deploy their own censorship-resistant, privacy-preserving communications node in minutes.
Our goal for Hack Week: package every component into containers built on openSUSE/MicroOS base images, initially orchestrated with a single container-compose.yml (podman-compose compatible). The stack will:
- Run on any host that supports Podman (including optimizations and enhancements for SELinux‑enabled systems).
- Allow network decoupling by refactoring configurations to move from file-system constrained Unix sockets to internal TCP networking, allowing containers achieve stricter isolation.
- Utilize Enhanced Security with SELinux by using purpose built utilities such as udica we can quickly generate custom SELinux policies for the container stack, ensuring strict confinement superior to standard/typical Docker deployments.
- Allow the use of bind or remote mounted volumes for shared data (
/var/vmail, DKIM keys, TLS certs, etc.). - Replace the local DNS server requirement with a remote DNS‑provider API for DKIM/TXT record publishing.
By delivering a turnkey, host agnostic, reproducible deployment, we lower the barrier for individuals and small communities to launch their own chatmail relays, fostering a decentralized, censorship‑resistant messaging ecosystem that can serve DeltaChat users and/or future services adopting this protocol
Resources
- The links included above
- https://chatmail.at/doc/relay/
- https://delta.chat/en/help
- Project repo -> https://codeberg.org/EndShittification/containerized-chatmail-relay
Exploring Rust's potential: from basics to security by sferracci
Description
This project aims to conduct a focused investigation and practical application of the Rust programming language, with a specific emphasis on its security model. A key component will be identifying and understanding the most common vulnerabilities that can be found in Rust code.
Goals
Achieve a beginner/intermediate level of proficiency in writing Rust code. This will be measured by trying to solve LeetCode problems focusing on common data structures and algorithms. Study Rust vulnerabilities and learning best practices to avoid them.
Resources
Rust book: https://doc.rust-lang.org/book/
Looking at Rust if it could be an interesting programming language by jsmeix
Get some basic understanding of Rust security related features from a general point of view.
This Hack Week project is not to learn Rust to become a Rust programmer. This might happen later but it is not the goal of this Hack Week project.
The goal of this Hack Week project is to evaluate if Rust could be an interesting programming language.
An interesting programming language must make it easier to write code that is correct and stays correct when over time others maintain and enhance it than the opposite.