Description
Backstage (backstage.io) is an open-source, CNCF project that allows you to create your own developer portal. There are many plugins for Backstage.
This could be a great compliment to Rancher Manager.
Goals
Learn and experiment with Backstage and look at how this could be integrated with Rancher Manager. Goal is to have some kind of integration completed in this Hack week.
Progress
Screen shot of home page at the end of Hackweek:
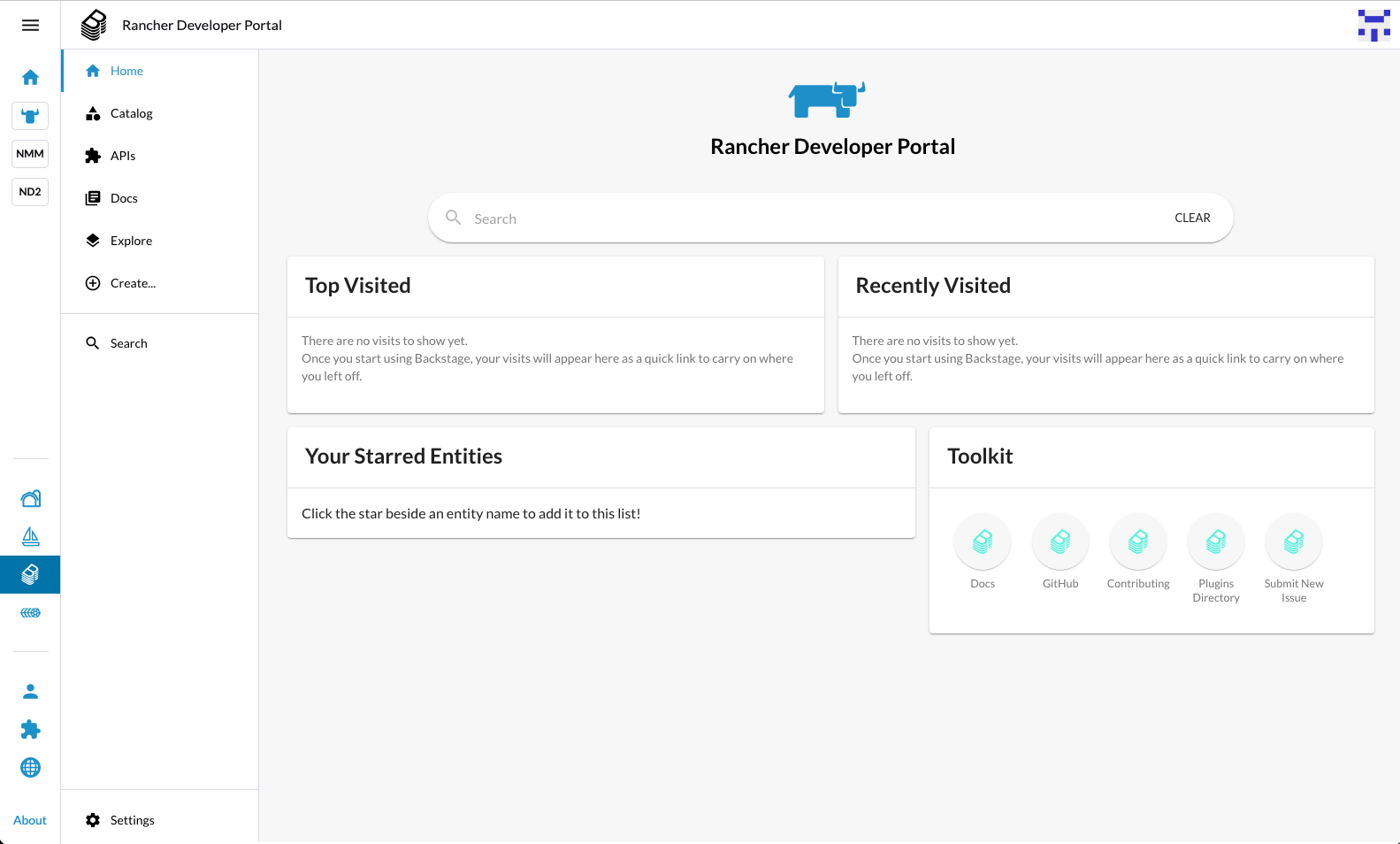
Day One
- Got Backstage running locally, understanding configuration with HTTPs.
- Got Backstage embedded in an IFRAME inside of Rancher
- Added content into the software catalog (see: https://backstage.io/docs/features/techdocs/getting-started/)
- Understood more about the entity model
Day Two
- Connected Backstage to the Rancher local cluster and configured the Kubernetes plugin.
- Created Rancher theme to make the light theme more consistent with Rancher
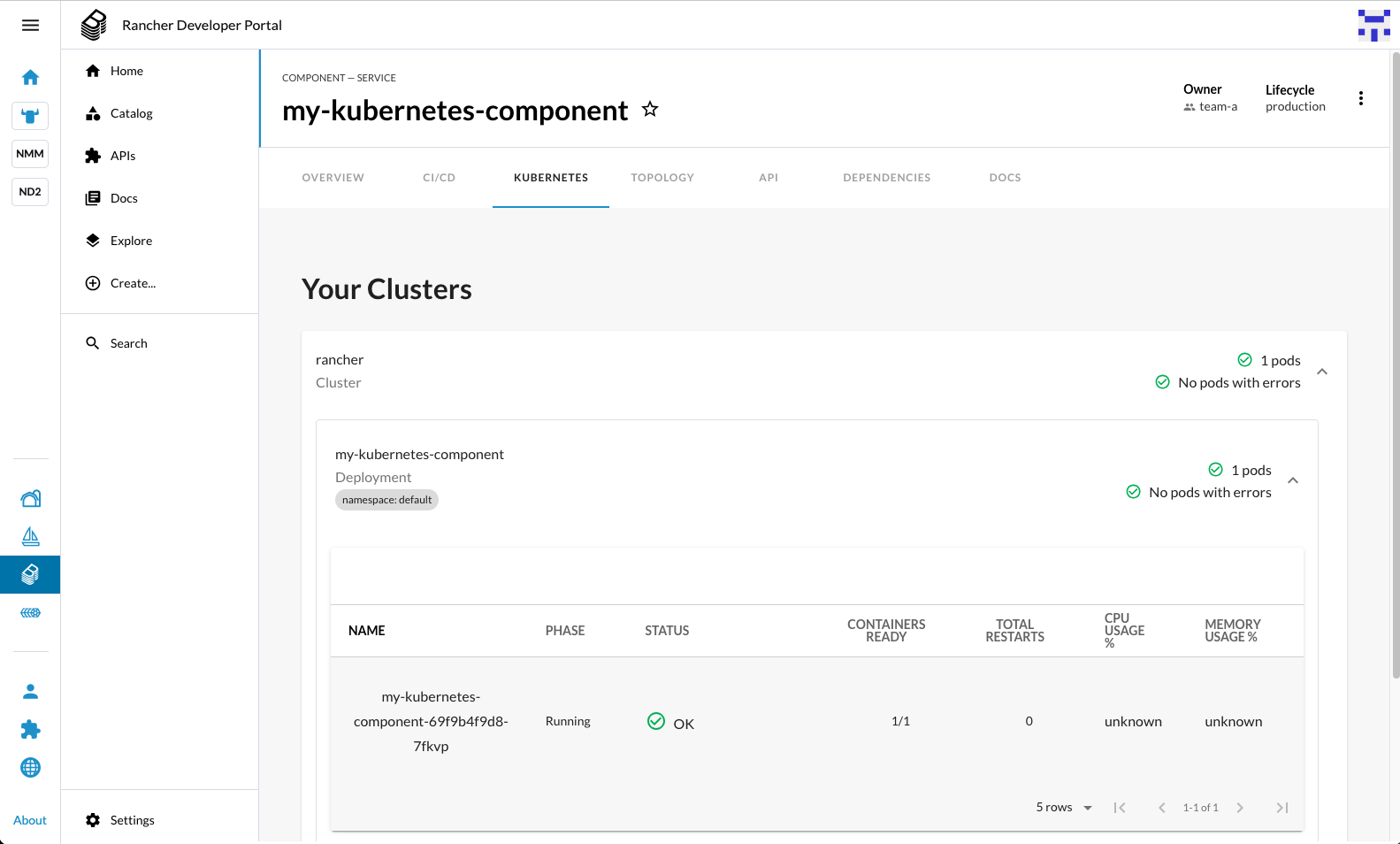
Days Three and Day Four
Created two backend plugins for Backstage:
- Catalog Entity Provider - this imports users from Rancher into Backstage
- Auth Provider - uses the proxied sign-in pattern to check the Rancher session cookie, to user that to authenticate the user with Rancher and then log them into Backstage by connecting this to the imported User entity from the catalog entity provider plugin.
With this in place, you can single-sign-on between Rancher and Backstage when it is deployed within Rancher. Note this is only when running locally for development at present

Day Five
- Start to build out a production deployment for all of the above
- Made some progress, but hit issues with the authentication and proxying when running proxied within Rancher, which needs further investigation

Looking for hackers with the skills:
This project is part of:
Hack Week 24
Activity
Comments
Be the first to comment!
Similar Projects
SUSE Virtualization (Harvester): VM Import UI flow by wombelix
Description
SUSE Virtualization (Harvester) has a vm-import-controller that allows migrating VMs from VMware and OpenStack, but users need to write manifest files and apply them with kubectl to use it. This project is about adding the missing UI pieces to the harvester-ui-extension, making VM Imports accessible without requiring Kubernetes and YAML knowledge.
VMware and OpenStack admins aren't automatically familiar with Kubernetes and YAML. Implementing the UI part for the VM Import feature makes it easier to use and more accessible. The Harvester Enhancement Proposal (HEP) VM Migration controller included a UI flow implementation in its scope. Issue #2274 received multiple comments that an UI integration would be a nice addition, and issue #4663 was created to request the implementation but eventually stalled.
Right now users need to manually create either VmwareSource or OpenstackSource resources, then write VirtualMachineImport manifests with network mappings and all the other configuration options. Users should be able to do that and track import status through the UI without writing YAML.
Work during the Hack Week will be done in this fork in a branch called suse-hack-week-25, making progress publicly visible and open for contributions. When everything works out and the branch is in good shape, it will be submitted as a pull request to harvester-ui-extension to get it included in the next Harvester release.
Testing will focus on VMware since that's what is available in the lab environment (SUSE Virtualization 1.6 single-node cluster, ESXi 8.0 standalone host). Given that this is about UI and surfacing what the vm-import-controller handles, the implementation should work for OpenStack imports as well.
This project is also a personal challenge to learn vue.js and get familiar with Rancher Extensions development, since harvester-ui-extension is built on that framework.
Goals
- Learn Vue.js and Rancher Extensions fundamentals required to finish the project
- Read and learn from other Rancher UI Extensions code, especially understanding the
harvester-ui-extensioncode base - Understand what the
vm-import-controllerand its CRDs require, identify ready to use components in the Rancher UI Extension API that can be leveraged - Implement UI logic for creating and managing
VmwareSource/OpenstackSourceandVirtualMachineImportresources with all relevant configuration options and credentials - Implemnt UI elements to display
VirtualMachineImportstatus and errors
Resources
HEP and related discussion
- https://github.com/harvester/harvester/blob/master/enhancements/20220726-vm-migration.md
- https://github.com/harvester/harvester/issues/2274
- https://github.com/harvester/harvester/issues/4663
SUSE Virtualization VM Import Documentation
Rancher Extensions Documentation
Rancher UI Plugin Examples
Vue Router Essentials
Vue Router API
Vuex Documentation
A CLI for Harvester by mohamed.belgaied
Harvester does not officially come with a CLI tool, the user is supposed to interact with Harvester mostly through the UI. Though it is theoretically possible to use kubectl to interact with Harvester, the manipulation of Kubevirt YAML objects is absolutely not user friendly. Inspired by tools like multipass from Canonical to easily and rapidly create one of multiple VMs, I began the development of Harvester CLI. Currently, it works but Harvester CLI needs some love to be up-to-date with Harvester v1.0.2 and needs some bug fixes and improvements as well.
Project Description
Harvester CLI is a command line interface tool written in Go, designed to simplify interfacing with a Harvester cluster as a user. It is especially useful for testing purposes as you can easily and rapidly create VMs in Harvester by providing a simple command such as:
harvester vm create my-vm --count 5
to create 5 VMs named my-vm-01 to my-vm-05.

Harvester CLI is functional but needs a number of improvements: up-to-date functionality with Harvester v1.0.2 (some minor issues right now), modifying the default behaviour to create an opensuse VM instead of an ubuntu VM, solve some bugs, etc.
Github Repo for Harvester CLI: https://github.com/belgaied2/harvester-cli
Done in previous Hackweeks
- Create a Github actions pipeline to automatically integrate Harvester CLI to Homebrew repositories: DONE
- Automatically package Harvester CLI for OpenSUSE / Redhat RPMs or DEBs: DONE
Goal for this Hackweek
The goal for this Hackweek is to bring Harvester CLI up-to-speed with latest Harvester versions (v1.3.X and v1.4.X), and improve the code quality as well as implement some simple features and bug fixes.
Some nice additions might be: * Improve handling of namespaced objects * Add features, such as network management or Load Balancer creation ? * Add more unit tests and, why not, e2e tests * Improve CI * Improve the overall code quality * Test the program and create issues for it
Issue list is here: https://github.com/belgaied2/harvester-cli/issues
Resources
The project is written in Go, and using client-go the Kubernetes Go Client libraries to communicate with the Harvester API (which is Kubernetes in fact).
Welcome contributions are:
- Testing it and creating issues
- Documentation
- Go code improvement
What you might learn
Harvester CLI might be interesting to you if you want to learn more about:
- GitHub Actions
- Harvester as a SUSE Product
- Go programming language
- Kubernetes API
- Kubevirt API objects (Manipulating VMs and VM Configuration in Kubernetes using Kubevirt)
Self-Scaling LLM Infrastructure Powered by Rancher by ademicev0
Self-Scaling LLM Infrastructure Powered by Rancher

Description
The Problem
Running LLMs can get expensive and complex pretty quickly.
Today there are typically two choices:
- Use cloud APIs like OpenAI or Anthropic. Easy to start with, but costs add up at scale.
- Self-host everything - set up Kubernetes, figure out GPU scheduling, handle scaling, manage model serving... it's a lot of work.
What if there was a middle ground?
What if infrastructure scaled itself instead of making you scale it?
Can we use existing Rancher capabilities like CAPI, autoscaling, and GitOps to make this simpler instead of building everything from scratch?
Project Repository: github.com/alexander-demicev/llmserverless
What This Project Does
A key feature is hybrid deployment: requests can be routed based on complexity or privacy needs. Simple or low-sensitivity queries can use public APIs (like OpenAI), while complex or private requests are handled in-house on local infrastructure. This flexibility allows balancing cost, privacy, and performance - using cloud for routine tasks and on-premises resources for sensitive or demanding workloads.
A complete, self-scaling LLM infrastructure that:
- Scales to zero when idle (no idle costs)
- Scales up automatically when requests come in
- Adds more nodes when needed, removes them when demand drops
- Runs on any infrastructure - laptop, bare metal, or cloud
Think of it as "serverless for LLMs" - focus on building, the infrastructure handles itself.
How It Works
A combination of open source tools working together:
Flow:
- Users interact with OpenWebUI (chat interface)
- Requests go to LiteLLM Gateway
- LiteLLM routes requests to:
- Ollama (Knative) for local model inference (auto-scales pods)
- Or cloud APIs for fallback
Rancher/k8s Trouble-Maker by tonyhansen
Project Description
When studying for my RHCSA, I found trouble-maker, which is a program that breaks a Linux OS and requires you to fix it. I want to create something similar for Rancher/k8s that can allow for troubleshooting an unknown environment.
Goals for Hackweek 25
- Update to modern Rancher and verify that existing tests still work
- Change testing logic to populate secrets instead of requiring a secondary script
- Add new tests
Goals for Hackweek 24 (Complete)
- Create a basic framework for creating Rancher/k8s cluster lab environments as needed for the Break/Fix
- Create at least 5 modules that can be applied to the cluster and require troubleshooting
Resources
- https://github.com/celidon/rancher-troublemaker
- https://github.com/rancher/terraform-provider-rancher2
- https://github.com/rancher/tf-rancher-up
- https://github.com/rancher/quickstart
Liz - Prompt autocomplete by ftorchia
Description
Liz is the Rancher AI assistant for cluster operations.
Goals
We want to help users when sending new messages to Liz, by adding an autocomplete feature to complete their requests based on the context.
Example:
- User prompt: "Can you show me the list of p"
- Autocomplete suggestion: "Can you show me the list of p...od in local cluster?"
Example:
- User prompt: "Show me the logs of #rancher-"
- Chat console: It shows a drop-down widget, next to the # character, with the list of available pod names starting with "rancher-".
Technical Overview
- The AI agent should expose a new ws/autocomplete endpoint to proxy autocomplete messages to the LLM.
- The UI extension should be able to display prompt suggestions and allow users to apply the autocomplete to the Prompt via keyboard shortcuts.
Resources
Rancher/k8s Trouble-Maker by tonyhansen
Project Description
When studying for my RHCSA, I found trouble-maker, which is a program that breaks a Linux OS and requires you to fix it. I want to create something similar for Rancher/k8s that can allow for troubleshooting an unknown environment.
Goals for Hackweek 25
- Update to modern Rancher and verify that existing tests still work
- Change testing logic to populate secrets instead of requiring a secondary script
- Add new tests
Goals for Hackweek 24 (Complete)
- Create a basic framework for creating Rancher/k8s cluster lab environments as needed for the Break/Fix
- Create at least 5 modules that can be applied to the cluster and require troubleshooting
Resources
- https://github.com/celidon/rancher-troublemaker
- https://github.com/rancher/terraform-provider-rancher2
- https://github.com/rancher/tf-rancher-up
- https://github.com/rancher/quickstart
A CLI for Harvester by mohamed.belgaied
Harvester does not officially come with a CLI tool, the user is supposed to interact with Harvester mostly through the UI. Though it is theoretically possible to use kubectl to interact with Harvester, the manipulation of Kubevirt YAML objects is absolutely not user friendly. Inspired by tools like multipass from Canonical to easily and rapidly create one of multiple VMs, I began the development of Harvester CLI. Currently, it works but Harvester CLI needs some love to be up-to-date with Harvester v1.0.2 and needs some bug fixes and improvements as well.
Project Description
Harvester CLI is a command line interface tool written in Go, designed to simplify interfacing with a Harvester cluster as a user. It is especially useful for testing purposes as you can easily and rapidly create VMs in Harvester by providing a simple command such as:
harvester vm create my-vm --count 5
to create 5 VMs named my-vm-01 to my-vm-05.
Harvester CLI is functional but needs a number of improvements: up-to-date functionality with Harvester v1.0.2 (some minor issues right now), modifying the default behaviour to create an opensuse VM instead of an ubuntu VM, solve some bugs, etc.
Github Repo for Harvester CLI: https://github.com/belgaied2/harvester-cli
Done in previous Hackweeks
- Create a Github actions pipeline to automatically integrate Harvester CLI to Homebrew repositories: DONE
- Automatically package Harvester CLI for OpenSUSE / Redhat RPMs or DEBs: DONE
Goal for this Hackweek
The goal for this Hackweek is to bring Harvester CLI up-to-speed with latest Harvester versions (v1.3.X and v1.4.X), and improve the code quality as well as implement some simple features and bug fixes.
Some nice additions might be: * Improve handling of namespaced objects * Add features, such as network management or Load Balancer creation ? * Add more unit tests and, why not, e2e tests * Improve CI * Improve the overall code quality * Test the program and create issues for it
Issue list is here: https://github.com/belgaied2/harvester-cli/issues
Resources
The project is written in Go, and using client-go the Kubernetes Go Client libraries to communicate with the Harvester API (which is Kubernetes in fact).
Welcome contributions are:
- Testing it and creating issues
- Documentation
- Go code improvement
What you might learn
Harvester CLI might be interesting to you if you want to learn more about:
- GitHub Actions
- Harvester as a SUSE Product
- Go programming language
- Kubernetes API
- Kubevirt API objects (Manipulating VMs and VM Configuration in Kubernetes using Kubevirt)
Technical talks at universities by agamez
Description
This project aims to empower the next generation of tech professionals by offering hands-on workshops on containerization and Kubernetes, with a strong focus on open-source technologies. By providing practical experience with these cutting-edge tools and fostering a deep understanding of open-source principles, we aim to bridge the gap between academia and industry.
For now, the scope is limited to Spanish universities, since we already have the contacts and have started some conversations.
Goals
- Technical Skill Development: equip students with the fundamental knowledge and skills to build, deploy, and manage containerized applications using open-source tools like Kubernetes.
- Open-Source Mindset: foster a passion for open-source software, encouraging students to contribute to open-source projects and collaborate with the global developer community.
- Career Readiness: prepare students for industry-relevant roles by exposing them to real-world use cases, best practices, and open-source in companies.
Resources
- Instructors: experienced open-source professionals with deep knowledge of containerization and Kubernetes.
- SUSE Expertise: leverage SUSE's expertise in open-source technologies to provide insights into industry trends and best practices.
Cluster API Provider for Harvester by rcase
Project Description
The Cluster API "infrastructure provider" for Harvester, also named CAPHV, makes it possible to use Harvester with Cluster API. This enables people and organisations to create Kubernetes clusters running on VMs created by Harvester using a declarative spec.
The project has been bootstrapped in HackWeek 23, and its code is available here.
Work done in HackWeek 2023
- Have a early working version of the provider available on Rancher Sandbox : *DONE *
- Demonstrated the created cluster can be imported using Rancher Turtles: DONE
- Stretch goal - demonstrate using the new provider with CAPRKE2: DONE and the templates are available on the repo
DONE in HackWeek 24:
- Add more Unit Tests
- Improve Status Conditions for some phases
- Add cloud provider config generation
- Testing with Harvester v1.3.2
- Template improvements
- Issues creation
DONE in 2025 (out of Hackweek)
- Support of ClusterClass
- Add to
clusterctlcommunity providers, you can add it directly withclusterctl - Testing on newer versions of Harvester v1.4.X and v1.5.X
- Support for
clusterctl generate cluster ... - Improve Status Conditions to reflect current state of Infrastructure
- Improve CI (some bugs for release creation)
Goals for HackWeek 2025
- FIRST and FOREMOST, any topic is important to you
- Add e2e testing
- Certify the provider for Rancher Turtles
- Add Machine pool labeling
- Add PCI-e passthrough capabilities.
- Other improvement suggestions are welcome!
Thanks to @isim and Dominic Giebert for their contributions!
Resources
Looking for help from anyone interested in Cluster API (CAPI) or who wants to learn more about Harvester.
This will be an infrastructure provider for Cluster API. Some background reading for the CAPI aspect:
OpenPlatform Self-Service Portal by tmuntan1
Description
In SUSE IT, we developed an internal developer platform for our engineers using SUSE technologies such as RKE2, SUSE Virtualization, and Rancher. While it works well for our existing users, the onboarding process could be better.
To improve our customer experience, I would like to build a self-service portal to make it easy for people to accomplish common actions. To get started, I would have the portal create Jira SD tickets for our customers to have better information in our tickets, but eventually I want to add automation to reduce our workload.
Goals
- Build a frontend website (Angular) that helps customers create Jira SD tickets.
- Build a backend (Rust with Axum) for the backend, which would do all the hard work for the frontend.
Resources (SUSE VPN only)
- development site: https://ui-dev.openplatform.suse.com/login?returnUrl=%2Fopenplatform%2Fforms
- https://gitlab.suse.de/itpe/core/open-platform/op-portal/backend
- https://gitlab.suse.de/itpe/core/open-platform/op-portal/frontend