Project Description
Idea is to predefine a set of security policies for popular container applications just for example MySQL, Nginx etc..., with these predefined security policies, users can just download unpack it to use. No need to worry too much about detailed security settings/configurations for this application container. The policies could be any policies that Kubernetes supported and/or NeuVector supported.
Today, there are security policies being supported by Kubernetes like NetworkPolicy, there are extended policies like KubeWarden admission control policies, there are advanced security policy like NeuVector's L7 network policy, process & file policy etc... All these policies are providing functions to secure a Kubernetes environment. From end user point of view, it is good but not convenient enough to use unless users are security experts. So idea is, we could create many predefined security policies for many popular container applications, define these as a Kubernetes standard format like CRD extension just for example. Make these the building blocks coupled with the app images, so when users pull a container, a security policy can be imported at same time. The basic security settings (baseline) will be in place right away. If NeuVector was installed already then the enforcement is in place as well. Most of the users will have basic security in place by doing almost nothing. (of course, if it's necessary, users can still customize or fine tune the predefined templates.)
Security needs to be easy to use but still strong enough to protect, a lot of security postures/configurations/policies could be already defined when this application container image is created. These security manifest is different per apps but it is relatively stable per container as well. So, if we can create or generate security policy templates for popular application images, eventually make some of solid ones a built-in template, or even grow to be a hosted security policy hub. It could be a new critical way to secure Kubernetes world.
Goal for this Hackweek
Study this deeper, choose a few popular applications and make a prototype/demo to proof the concept.
Resources
Some of the policies might not be a good fit to be profiled as manifest. Here we will be focusing on relatively stable application security posture/configuration/runtime policies. Starting point could be look into these:
https://open-docs.neuvector.com/policy/overview
https://kubernetes.io/docs/concepts/services-networking/network-policies/
https://docs.kubewarden.io/writing-policies
https://kyverno.io/docs/kyverno-policies/
No Hackers yet
Looking for hackers with the skills:
This project is part of:
Hack Week 23
Activity
Comments
Be the first to comment!
Similar Projects
Exploring Rust's potential: from basics to security by sferracci
Description
This project aims to conduct a focused investigation and practical application of the Rust programming language, with a specific emphasis on its security model. A key component will be identifying and understanding the most common vulnerabilities that can be found in Rust code.
Goals
Achieve a beginner/intermediate level of proficiency in writing Rust code. This will be measured by trying to solve LeetCode problems focusing on common data structures and algorithms. Study Rust vulnerabilities and learning best practices to avoid them.
Resources
Rust book: https://doc.rust-lang.org/book/
Looking at Rust if it could be an interesting programming language by jsmeix
Get some basic understanding of Rust security related features from a general point of view.
This Hack Week project is not to learn Rust to become a Rust programmer. This might happen later but it is not the goal of this Hack Week project.
The goal of this Hack Week project is to evaluate if Rust could be an interesting programming language.
An interesting programming language must make it easier to write code that is correct and stays correct when over time others maintain and enhance it than the opposite.
OSHW USB token for Passkeys (FIDO2, U2F, WebAuthn) and PGP by duwe
Description
The idea to carry your precious key material along in a specially secured hardware item is almost as old as public keys themselves, starting with the OpenPGP card. Nowadays, an USB plug or NFC are the hardware interfaces of choice, and password-less log-ins are fortunately becoming more popular and standardised.
Meanwhile there are a few products available in that field, for example
yubikey - the "market leader", who continues to sell off buggy, allegedly unfixable firmware ROMs from old stock. Needless to say, it's all but open source, so assume backdoors.
nitrokey - the "start" variant is open source, but the hardware was found to leak its flash ROM content via the SWD debugging interface (even when the flash is read protected !) Compute power is barely enough for Curve25519, Flash memory leaves room for only 3 keys.
solokey(2) - quite neat hardware, with a secure enclave called "TrustZone-M". Unfortunately, the OSS firmware development is stuck in a rusty dead end and cannot use it. Besides, NXP's support for open source toolchains for its devboards is extremely limited.
I plan to base this project on the not-so-tiny USB stack, which is extremely easy to retarget, and to rewrite / refactor the crypto protocols to use the keys only via handles, so the actual key material can be stored securely. Best OSS support seems to be for STM32-based products.
Goals
Create a proof-of-concept item that can provide a second factor for logins and/or decrypt a PGP mail with your private key without disclosing the key itself. Implement or at least show a migration path to store the private key in a location with elevated hardware security.
Resources
STM32 Nucleo, blackmagic probe, tropicsquare tropic01, arm-none cross toolchain
vex8s-controller: a kubernetes controller to automatically generate VEX documents of your running workloads by agreggi

Description
vex8s-controller is an add-on for SBOMscanner project.
Its purpose is to automatically generate VEX documents based on the workloads running in a kubernetes cluster. It integrates directly with SBOMscanner by monitoring VulnerabilityReports created for container images and producing corresponding VEX documents that reflect each workload’s SecurityContext.
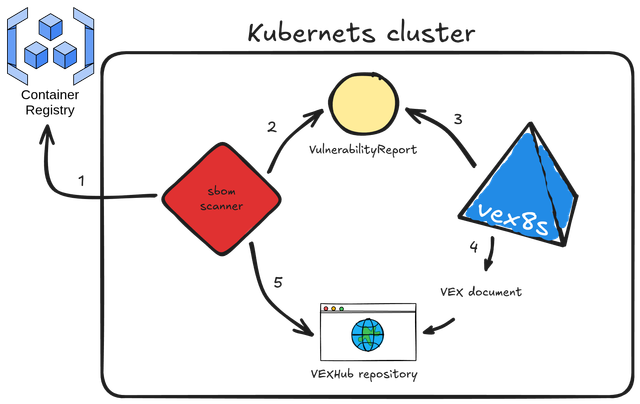
Here's the workflow explained:
- sbomscanner scans for images in registry
- generates a
VulnerabilityReportwith the image CVEs - vex8s-controller triggers when a workload is scheduled on the cluster and generates a VEX document based on the workload
SecurityContextconfiguration - the VEX document is provided by vex8s-controller using a VEX Hub repository
- sbomscanner configure the VEXHub CRD to point to the internal vex8s-controller VEX Hub repository
Goals
The objective is to build a kubernetes controller that uses the vex8s mitigation rules engine to generate VEX documents and serve them through an internal VEX Hub repository within the cluster.
SBOMscanner can then be configured to consume VEX data directly from this in-cluster repository managed by vex8s-controller.
Resources
Summary
The project ended up with this PoC on GitHub: vex8s-controller.
The controller works fine, but needs work to make it more stable. Instructions to reproduce a demo locally are reported in the repository.
Help Create A Chat Control Resistant Turnkey Chatmail/Deltachat Relay Stack - Rootless Podman Compose, OpenSUSE BCI, Hardened, & SELinux by 3nd5h1771fy
Description
The Mission: Decentralized & Sovereign Messaging
FYI: If you have never heard of "Chatmail", you can visit their site here, but simply put it can be thought of as the underlying protocol/platform decentralized messengers like DeltaChat use for their communications. Do not confuse it with the honeypot looking non-opensource paid for prodect with better seo that directs you to chatmailsecure(dot)com
In an era of increasing centralized surveillance by unaccountable bad actors (aka BigTech), "Chat Control," and the erosion of digital privacy, the need for sovereign communication infrastructure is critical. Chatmail is a pioneering initiative that bridges the gap between classic email and modern instant messaging, offering metadata-minimized, end-to-end encrypted (E2EE) communication that is interoperable and open.
However, unless you are a seasoned sysadmin, the current recommended deployment method of a Chatmail relay is rigid, fragile, difficult to properly secure, and effectively takes over the entire host the "relay" is deployed on.
Why This Matters
A simple, host agnostic, reproducible deployment lowers the entry cost for anyone wanting to run a privacy‑preserving, decentralized messaging relay. In an era of perpetually resurrected chat‑control legislation threats, EU digital‑sovereignty drives, and many dangers of using big‑tech messaging platforms (Apple iMessage, WhatsApp, FB Messenger, Instagram, SMS, Google Messages, etc...) for any type of communication, providing an easy‑to‑use alternative empowers:
- Censorship resistance - No single entity controls the relay; operators can spin up new nodes quickly.
- Surveillance mitigation - End‑to‑end OpenPGP encryption ensures relay operators never see plaintext.
- Digital sovereignty - Communities can host their own infrastructure under local jurisdiction, aligning with national data‑policy goals.
By turning the Chatmail relay into a plug‑and‑play container stack, we enable broader adoption, foster a resilient messaging fabric, and give developers, activists, and hobbyists a concrete tool to defend privacy online.
Goals
As I indicated earlier, this project aims to drastically simplify the deployment of Chatmail relay. By converting this architecture into a portable, containerized stack using Podman and OpenSUSE base container images, we can allow anyone to deploy their own censorship-resistant, privacy-preserving communications node in minutes.
Our goal for Hack Week: package every component into containers built on openSUSE/MicroOS base images, initially orchestrated with a single container-compose.yml (podman-compose compatible). The stack will:
- Run on any host that supports Podman (including optimizations and enhancements for SELinux‑enabled systems).
- Allow network decoupling by refactoring configurations to move from file-system constrained Unix sockets to internal TCP networking, allowing containers achieve stricter isolation.
- Utilize Enhanced Security with SELinux by using purpose built utilities such as udica we can quickly generate custom SELinux policies for the container stack, ensuring strict confinement superior to standard/typical Docker deployments.
- Allow the use of bind or remote mounted volumes for shared data (
/var/vmail, DKIM keys, TLS certs, etc.). - Replace the local DNS server requirement with a remote DNS‑provider API for DKIM/TXT record publishing.
By delivering a turnkey, host agnostic, reproducible deployment, we lower the barrier for individuals and small communities to launch their own chatmail relays, fostering a decentralized, censorship‑resistant messaging ecosystem that can serve DeltaChat users and/or future services adopting this protocol
Resources
- The links included above
- https://chatmail.at/doc/relay/
- https://delta.chat/en/help
- Project repo -> https://codeberg.org/EndShittification/containerized-chatmail-relay
Cluster API Provider for Harvester by rcase
Project Description
The Cluster API "infrastructure provider" for Harvester, also named CAPHV, makes it possible to use Harvester with Cluster API. This enables people and organisations to create Kubernetes clusters running on VMs created by Harvester using a declarative spec.
The project has been bootstrapped in HackWeek 23, and its code is available here.
Work done in HackWeek 2023
- Have a early working version of the provider available on Rancher Sandbox : *DONE *
- Demonstrated the created cluster can be imported using Rancher Turtles: DONE
- Stretch goal - demonstrate using the new provider with CAPRKE2: DONE and the templates are available on the repo
DONE in HackWeek 24:
- Add more Unit Tests
- Improve Status Conditions for some phases
- Add cloud provider config generation
- Testing with Harvester v1.3.2
- Template improvements
- Issues creation
DONE in 2025 (out of Hackweek)
- Support of ClusterClass
- Add to
clusterctlcommunity providers, you can add it directly withclusterctl - Testing on newer versions of Harvester v1.4.X and v1.5.X
- Support for
clusterctl generate cluster ... - Improve Status Conditions to reflect current state of Infrastructure
- Improve CI (some bugs for release creation)
Goals for HackWeek 2025
- FIRST and FOREMOST, any topic is important to you
- Add e2e testing
- Certify the provider for Rancher Turtles
- Add Machine pool labeling
- Add PCI-e passthrough capabilities.
- Other improvement suggestions are welcome!
Thanks to @isim and Dominic Giebert for their contributions!
Resources
Looking for help from anyone interested in Cluster API (CAPI) or who wants to learn more about Harvester.
This will be an infrastructure provider for Cluster API. Some background reading for the CAPI aspect:
Preparing KubeVirtBMC for project transfer to the KubeVirt organization by zchang
Description
KubeVirtBMC is preparing to transfer the project to the KubeVirt organization. One requirement is to enhance the modeling design's security. The current v1alpha1 API (the VirtualMachineBMC CRD) was designed during the proof-of-concept stage. It's immature and inherently insecure due to its cross-namespace object references, exposing security concerns from an RBAC perspective.
The other long-awaited feature is the ability to mount virtual media so that virtual machines can boot from remote ISO images.
Goals
- Deliver the v1beta1 API and its corresponding controller implementation
- Enable the Redfish virtual media mount function for KubeVirt virtual machines
Resources
- The KubeVirtBMC repo: https://github.com/starbops/kubevirtbmc
- The new v1beta1 API: https://github.com/starbops/kubevirtbmc/issues/83
- Redfish virtual media mount: https://github.com/starbops/kubevirtbmc/issues/44
The Agentic Rancher Experiment: Do Androids Dream of Electric Cattle? by moio
Rancher is a beast of a codebase. Let's investigate if the new 2025 generation of GitHub Autonomous Coding Agents and Copilot Workspaces can actually tame it. 
The Plan
Create a sandbox GitHub Organization, clone in key Rancher repositories, and let the AI loose to see if it can handle real-world enterprise OSS maintenance - or if it just hallucinates new breeds of Kubernetes resources!
Specifically, throw "Agentic Coders" some typical tasks in a complex, long-lived open-source project, such as:
❥ The Grunt Work: generate missing GoDocs, unit tests, and refactorings. Rebase PRs.
❥ The Complex Stuff: fix actual (historical) bugs and feature requests to see if they can traverse the complexity without (too much) human hand-holding.
❥ Hunting Down Gaps: find areas lacking in docs, areas of improvement in code, dependency bumps, and so on.
If time allows, also experiment with Model Context Protocol (MCP) to give agents context on our specific build pipelines and CI/CD logs.
Why?
We know AI can write "Hello World." and also moderately complex programs from a green field. But can it rebase a 3-month-old PR with conflicts in rancher/rancher? I want to find the breaking point of current AI agents to determine if and how they can help us to reduce our technical debt, work faster and better. At the same time, find out about pitfalls and shortcomings.
The CONCLUSION!!!
A ![]() State of the Union
State of the Union ![]() document was compiled to summarize lessons learned this week. For more gory details, just read on the diary below!
document was compiled to summarize lessons learned this week. For more gory details, just read on the diary below! ![]()
Technical talks at universities by agamez
Description
This project aims to empower the next generation of tech professionals by offering hands-on workshops on containerization and Kubernetes, with a strong focus on open-source technologies. By providing practical experience with these cutting-edge tools and fostering a deep understanding of open-source principles, we aim to bridge the gap between academia and industry.
For now, the scope is limited to Spanish universities, since we already have the contacts and have started some conversations.
Goals
- Technical Skill Development: equip students with the fundamental knowledge and skills to build, deploy, and manage containerized applications using open-source tools like Kubernetes.
- Open-Source Mindset: foster a passion for open-source software, encouraging students to contribute to open-source projects and collaborate with the global developer community.
- Career Readiness: prepare students for industry-relevant roles by exposing them to real-world use cases, best practices, and open-source in companies.
Resources
- Instructors: experienced open-source professionals with deep knowledge of containerization and Kubernetes.
- SUSE Expertise: leverage SUSE's expertise in open-source technologies to provide insights into industry trends and best practices.
A CLI for Harvester by mohamed.belgaied
Harvester does not officially come with a CLI tool, the user is supposed to interact with Harvester mostly through the UI. Though it is theoretically possible to use kubectl to interact with Harvester, the manipulation of Kubevirt YAML objects is absolutely not user friendly. Inspired by tools like multipass from Canonical to easily and rapidly create one of multiple VMs, I began the development of Harvester CLI. Currently, it works but Harvester CLI needs some love to be up-to-date with Harvester v1.0.2 and needs some bug fixes and improvements as well.
Project Description
Harvester CLI is a command line interface tool written in Go, designed to simplify interfacing with a Harvester cluster as a user. It is especially useful for testing purposes as you can easily and rapidly create VMs in Harvester by providing a simple command such as:
harvester vm create my-vm --count 5
to create 5 VMs named my-vm-01 to my-vm-05.

Harvester CLI is functional but needs a number of improvements: up-to-date functionality with Harvester v1.0.2 (some minor issues right now), modifying the default behaviour to create an opensuse VM instead of an ubuntu VM, solve some bugs, etc.
Github Repo for Harvester CLI: https://github.com/belgaied2/harvester-cli
Done in previous Hackweeks
- Create a Github actions pipeline to automatically integrate Harvester CLI to Homebrew repositories: DONE
- Automatically package Harvester CLI for OpenSUSE / Redhat RPMs or DEBs: DONE
Goal for this Hackweek
The goal for this Hackweek is to bring Harvester CLI up-to-speed with latest Harvester versions (v1.3.X and v1.4.X), and improve the code quality as well as implement some simple features and bug fixes.
Some nice additions might be: * Improve handling of namespaced objects * Add features, such as network management or Load Balancer creation ? * Add more unit tests and, why not, e2e tests * Improve CI * Improve the overall code quality * Test the program and create issues for it
Issue list is here: https://github.com/belgaied2/harvester-cli/issues
Resources
The project is written in Go, and using client-go the Kubernetes Go Client libraries to communicate with the Harvester API (which is Kubernetes in fact).
Welcome contributions are:
- Testing it and creating issues
- Documentation
- Go code improvement
What you might learn
Harvester CLI might be interesting to you if you want to learn more about:
- GitHub Actions
- Harvester as a SUSE Product
- Go programming language
- Kubernetes API
- Kubevirt API objects (Manipulating VMs and VM Configuration in Kubernetes using Kubevirt)
Technical talks at universities by agamez
Description
This project aims to empower the next generation of tech professionals by offering hands-on workshops on containerization and Kubernetes, with a strong focus on open-source technologies. By providing practical experience with these cutting-edge tools and fostering a deep understanding of open-source principles, we aim to bridge the gap between academia and industry.
For now, the scope is limited to Spanish universities, since we already have the contacts and have started some conversations.
Goals
- Technical Skill Development: equip students with the fundamental knowledge and skills to build, deploy, and manage containerized applications using open-source tools like Kubernetes.
- Open-Source Mindset: foster a passion for open-source software, encouraging students to contribute to open-source projects and collaborate with the global developer community.
- Career Readiness: prepare students for industry-relevant roles by exposing them to real-world use cases, best practices, and open-source in companies.
Resources
- Instructors: experienced open-source professionals with deep knowledge of containerization and Kubernetes.
- SUSE Expertise: leverage SUSE's expertise in open-source technologies to provide insights into industry trends and best practices.
Help Create A Chat Control Resistant Turnkey Chatmail/Deltachat Relay Stack - Rootless Podman Compose, OpenSUSE BCI, Hardened, & SELinux by 3nd5h1771fy
Description
The Mission: Decentralized & Sovereign Messaging
FYI: If you have never heard of "Chatmail", you can visit their site here, but simply put it can be thought of as the underlying protocol/platform decentralized messengers like DeltaChat use for their communications. Do not confuse it with the honeypot looking non-opensource paid for prodect with better seo that directs you to chatmailsecure(dot)com
In an era of increasing centralized surveillance by unaccountable bad actors (aka BigTech), "Chat Control," and the erosion of digital privacy, the need for sovereign communication infrastructure is critical. Chatmail is a pioneering initiative that bridges the gap between classic email and modern instant messaging, offering metadata-minimized, end-to-end encrypted (E2EE) communication that is interoperable and open.
However, unless you are a seasoned sysadmin, the current recommended deployment method of a Chatmail relay is rigid, fragile, difficult to properly secure, and effectively takes over the entire host the "relay" is deployed on.
Why This Matters
A simple, host agnostic, reproducible deployment lowers the entry cost for anyone wanting to run a privacy‑preserving, decentralized messaging relay. In an era of perpetually resurrected chat‑control legislation threats, EU digital‑sovereignty drives, and many dangers of using big‑tech messaging platforms (Apple iMessage, WhatsApp, FB Messenger, Instagram, SMS, Google Messages, etc...) for any type of communication, providing an easy‑to‑use alternative empowers:
- Censorship resistance - No single entity controls the relay; operators can spin up new nodes quickly.
- Surveillance mitigation - End‑to‑end OpenPGP encryption ensures relay operators never see plaintext.
- Digital sovereignty - Communities can host their own infrastructure under local jurisdiction, aligning with national data‑policy goals.
By turning the Chatmail relay into a plug‑and‑play container stack, we enable broader adoption, foster a resilient messaging fabric, and give developers, activists, and hobbyists a concrete tool to defend privacy online.
Goals
As I indicated earlier, this project aims to drastically simplify the deployment of Chatmail relay. By converting this architecture into a portable, containerized stack using Podman and OpenSUSE base container images, we can allow anyone to deploy their own censorship-resistant, privacy-preserving communications node in minutes.
Our goal for Hack Week: package every component into containers built on openSUSE/MicroOS base images, initially orchestrated with a single container-compose.yml (podman-compose compatible). The stack will:
- Run on any host that supports Podman (including optimizations and enhancements for SELinux‑enabled systems).
- Allow network decoupling by refactoring configurations to move from file-system constrained Unix sockets to internal TCP networking, allowing containers achieve stricter isolation.
- Utilize Enhanced Security with SELinux by using purpose built utilities such as udica we can quickly generate custom SELinux policies for the container stack, ensuring strict confinement superior to standard/typical Docker deployments.
- Allow the use of bind or remote mounted volumes for shared data (
/var/vmail, DKIM keys, TLS certs, etc.). - Replace the local DNS server requirement with a remote DNS‑provider API for DKIM/TXT record publishing.
By delivering a turnkey, host agnostic, reproducible deployment, we lower the barrier for individuals and small communities to launch their own chatmail relays, fostering a decentralized, censorship‑resistant messaging ecosystem that can serve DeltaChat users and/or future services adopting this protocol
Resources
- The links included above
- https://chatmail.at/doc/relay/
- https://delta.chat/en/help
- Project repo -> https://codeberg.org/EndShittification/containerized-chatmail-relay
Rewrite Distrobox in go (POC) by fabriziosestito
Description
Rewriting Distrobox in Go.
Main benefits:
- Easier to maintain and to test
- Adapter pattern for different container backends (LXC, systemd-nspawn, etc.)
Goals
- Build a minimal starting point with core commands
- Keep the CLI interface compatible: existing users shouldn't notice any difference
- Use a clean Go architecture with adapters for different container backends
- Keep dependencies minimal and binary size small
- Benchmark against the original shell script
Resources
- Upstream project: https://github.com/89luca89/distrobox/
- Distrobox site: https://distrobox.it/
- ArchWiki: https://wiki.archlinux.org/title/Distrobox
Port the classic browser game HackTheNet to PHP 8 by dgedon
Description
The classic browser game HackTheNet from 2004 still runs on PHP 4/5 and MySQL 5 and needs a port to PHP 8 and e.g. MariaDB.
Goals
- Port the game to PHP 8 and MariaDB 11
- Create a container where the game server can simply be started/stopped
Resources
- https://github.com/nodeg/hackthenet